
AIや機械学習の話題において、ディープラーニングという言葉がセットで語られることは多いです。
ディープラーニングは機械学習の手法のひとつであり、もちろん他にも機械学習の手法があります。
それでも特に「ディープラーニングとはどんなものか?」が知りたい人にとって、「ゼロから作るDeep Learning」は最適です。
このエントリでは「ゼロから作るDeep Learning」の内容をまとめます。
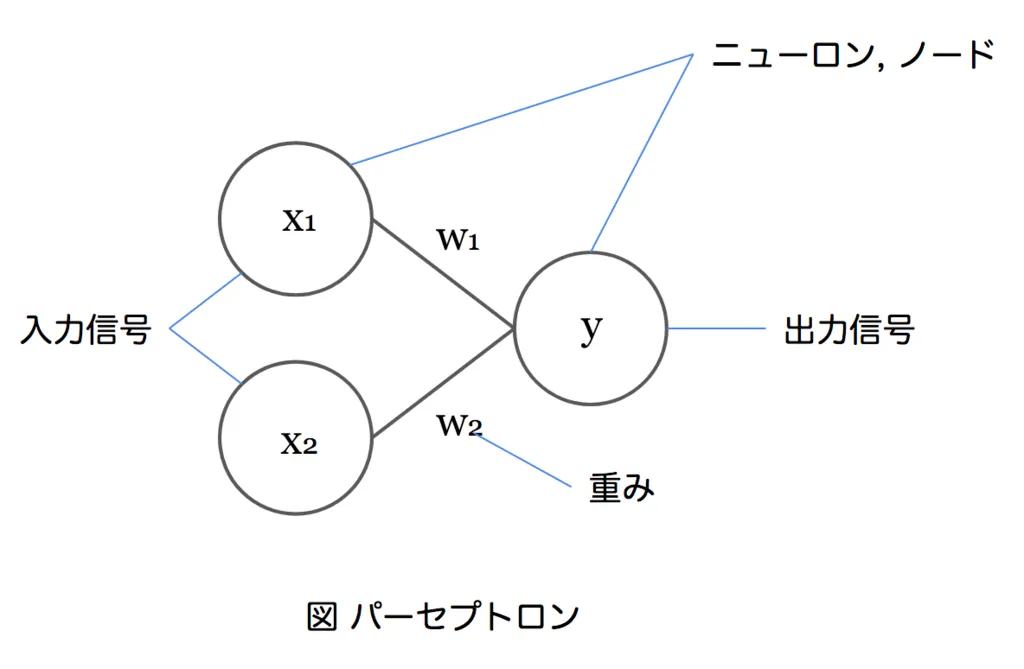
ニューラルネットワークのベースとなる考え方。
出力信号は入力信号にそれぞれ重みを乗じたものの総和となる。
ニューロンの入力信号の総和を出力信号に変換する関数。h(a) のように表記される。
活性化関数としてはステップ関数、シグモイド関数、ReLU などがある。
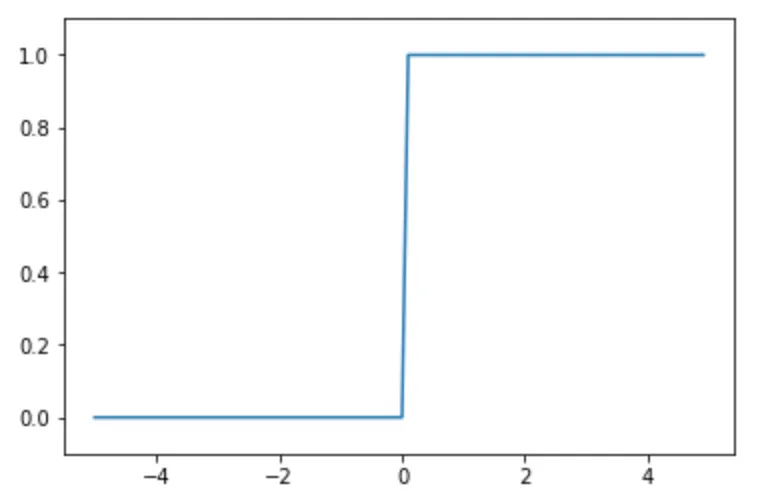
0より大きいときは1を、0以下のときは0を出力する。
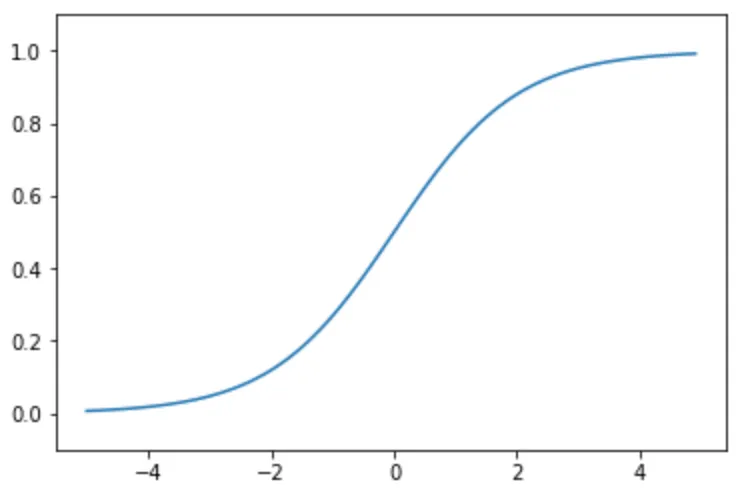
y = 1 / 1 + exp(-x)
ステップ関数とは異なり、0から1まで滑らかに変化する。
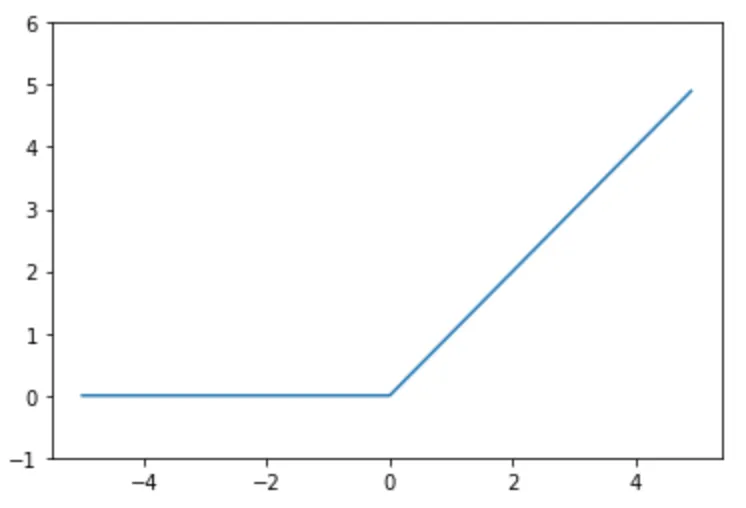
y = max(0, x)
0以下のときは何も出力せず、0より大きいときは入力信号をそのまま出力する。
出力層の活性化関数には恒等関数とソフトマックス関数が利用される。
一般に、回帰問題では恒等関数が、分類問題ではソフトマックス関数が用いられる。
入力をそのまま出力する。
確率のように、全ての出力の総和が1になるように正規化する。
手書き数字のデータセット。機械学習の分野で広く利用されている。
ニューラルネットワークの性能の悪さを表す指標。二乗和誤差や交差エントロピー誤差などが用いられる。
損失関数の最小値を探索するための方法。坂道を下るように、勾配が大きい方に向かってパラメータを更新していく。
勾配の計算を効率よく行うための手法。
学習の目的は重みのパラメータを最適化することにある。パラメータの更新アルゴリズムは次のようなものがある。
- 確率的勾配降下法 (SGD: Stochastic Gradient Descent)
- シンプルだが勾配によっては (お椀をx軸方向に引き伸ばしたような) 効率が悪くなってしまう
- Momentum
- 物体の運動量に着目したアルゴリズム
- AdaGrad
- 学習率の減衰 (Learning Rate Decay) というアイデアを取り入れたアルゴリズム
- Adam
- Momentum と AdaGrad を組み合わせたようなアルゴリズム
SGD は今でも多くの研究者に使われているが、最近では Adam が好んで使われる傾向がある。
訓練データに対して適合し過ぎてしまい訓練データに含まれない他のデータに対してうまく対応できない状態のこと。
過学習を抑制する手法として Weight Decay や Dropout などがある。
学習の過程において大きな重みを持つことにペナルティを課す手法。
ニューロンをランダムに消去しながら学習する手法。
畳み込み層とプーリング層を持つニューラルネットワークで、画像認識分野で効果を上げている。
畳み込み層は全結合層とは異なり、入力データの空間的な情報 (形状) を維持したまま次の層にデータを出力する。
CNN では畳み込み層の入出力データを特徴マップ (Feature Map) と呼ぶ。
プーリング層ではフィルターの領域を1つの代表値に集約する処理を行い、微小なズレに対する頑健性 (ロバスト性) を高める。
フィルター領域の代表として最大値を用いる手法を Max プーリングと呼ぶ。画像認識の分野では主に Max プーリングが使われる。
層を何層にも深くしたニューラルネットワーク。計算量が膨大になるため GPU 性能の向上や分散学習、ビット制度の削減などが高速化を支えている。
以上です。
このエントリでは「ゼロから作るDeep Learning」の内容をまとめました。
機械学習やディープラーニングは、プログラミング言語を学習するのとはまったく違った難しさがあり、検索した情報だけで学習するのは困難です。
ぜひ書籍から体系的に学習をしてみてください。
ディープラーニング以外の機械学習について知りたい方は下記の記事が参考になりそうです。
コメントを送る
コメントはブログオーナーのみ閲覧できます