
機械学習でテキスト(自然言語)を扱おうとすると必ずと言っていいほど目にするのが「word2vec」だ。
このエントリでは「word2vecによる自然言語処理」の内容をまとめる。
ニューラルネットワークをはじめとした機械学習で自然言語を扱うには、単語などをベクトルで表す必要がある。
word2vec は単語をベクトルに変換するための手法の1つで、分散表現とも呼ばれる。
word2vec では意味の近い単語は近いベクトルになるとされる。
例としては king - man + woman = queen は「王様から男を引いて女を足したら女王になる」というのがある。
word2vec のモデルの1つである Skip-gram はニューラルネットワークが基礎となっている。
Skip-gram のニューラルネットワークは、入力層と出力層の次元数が単語数であるのに対し、中間層の次元数は200次元と小さくなっている。
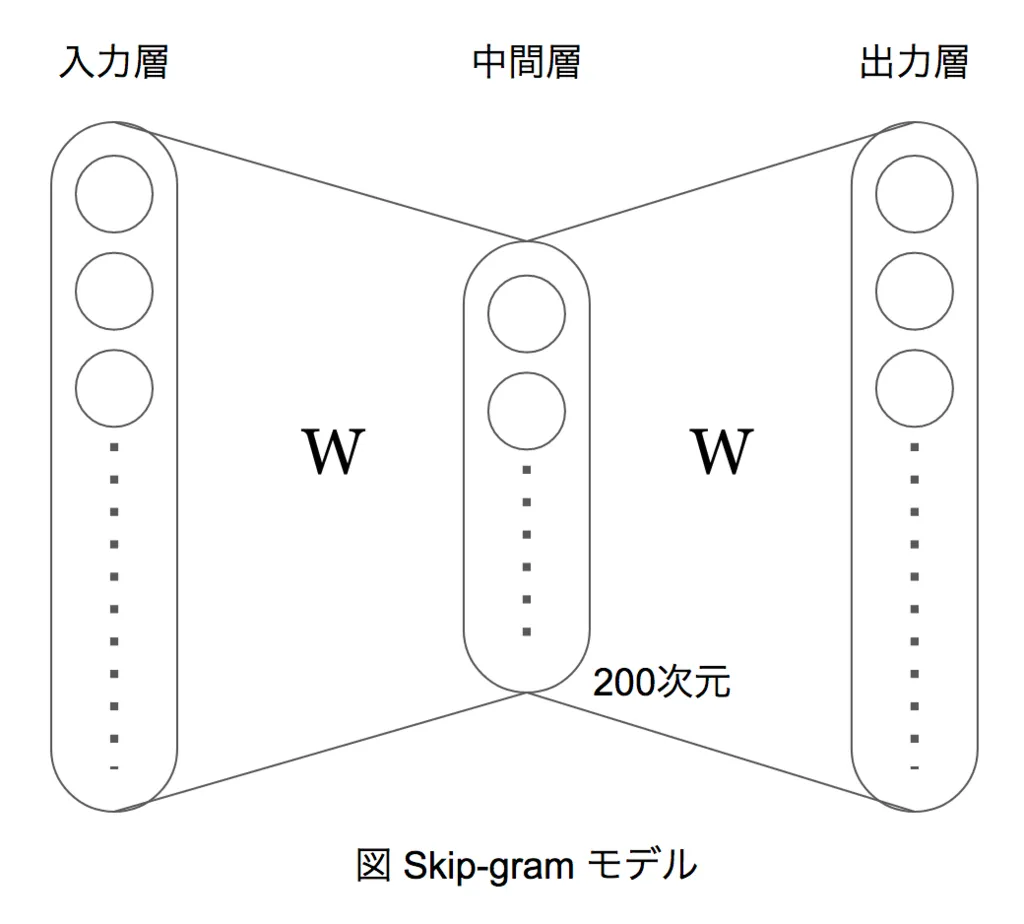
これにより入力データは中間層で無理やり次元圧縮され、入力データの特徴を表すベクトルが得られる。
計算の高速化のために階層的ソフトマックスやネガティブサンプリングといった手法がある。
階層的ソフトマックスは、頻度の高い単語の順にハフマン木を作り、各階層ごとにロジスティック回帰を使うことでソフトマックスを近似する手法である。
ソフトマックスを階層的に適用するわけではないので注意が必要だ。
ネガティブサンプリングは、ランダムに偽の入力を与え、偽の入力によって正解が出る確率を下げるように学習する手法である。
単語をベクトル化し、意味の近い単語が近いベクトルになる。異なる言語でも同じ傾向があるようだ。
word2vec でベクトル化すると意味の近い単語が近いベクトルになるため、k-means などのクラスタリングを使えば表記揺れの吸収に応用できそうだ。
一方、word2vec は単語ごとにベクトル化することから多義語の扱いは苦手である。
出現頻度の高い単語の意味が強く反映されてしまったり、どちらの類義語とも遠いベクトルになってしまったりする。
以上、このエントリでは「word2vecによる自然言語処理」の内容をまとめた。
コメントを送る
コメントはブログオーナーのみ閲覧できます